What is SEdb 3.0?
Super-enhancers are a large cluster of transcriptionally active enhancers enriched in enhancer-associated chromatin characteristics. Compared to typical enhancers, super-enhancers are larger, exhibit higher transcription factor density, and are frequently associated with key lineage-specific genes that control cell state and differentiation in somatic cells.
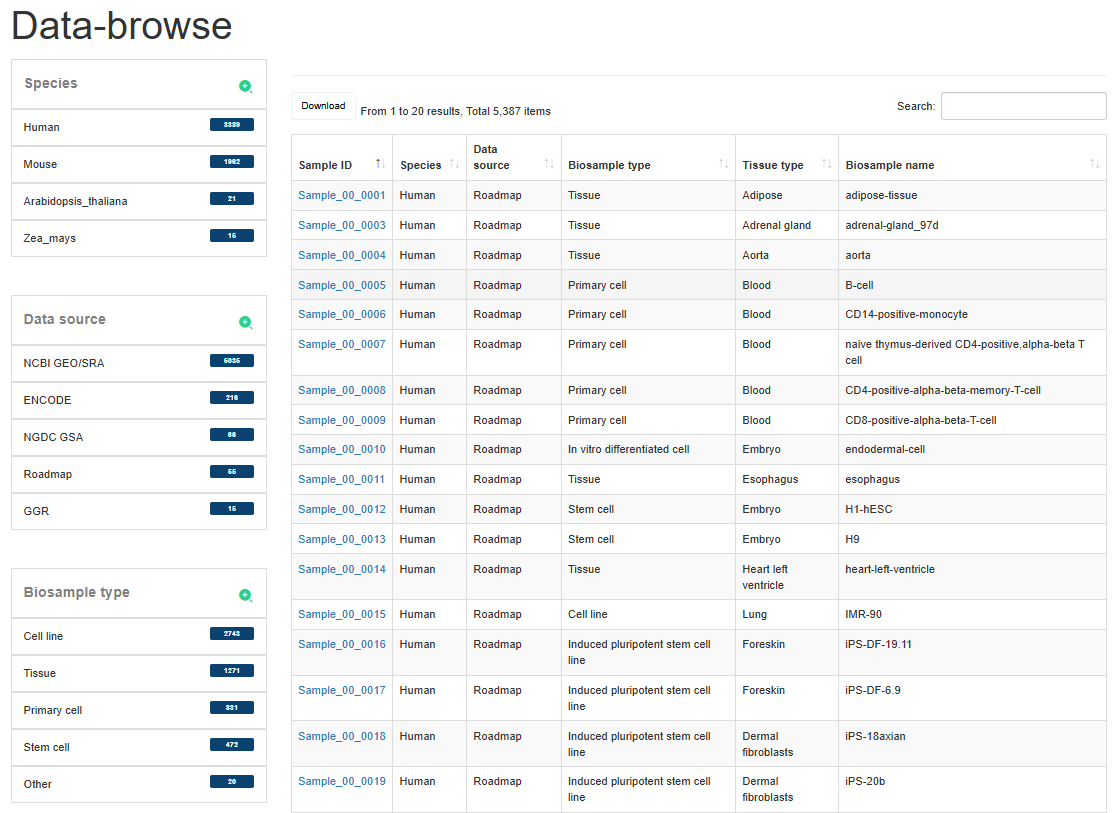
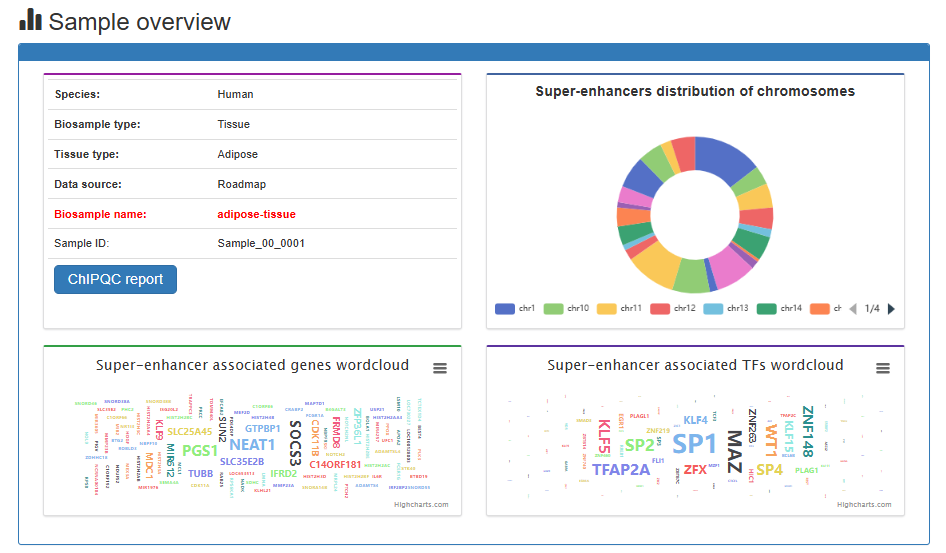
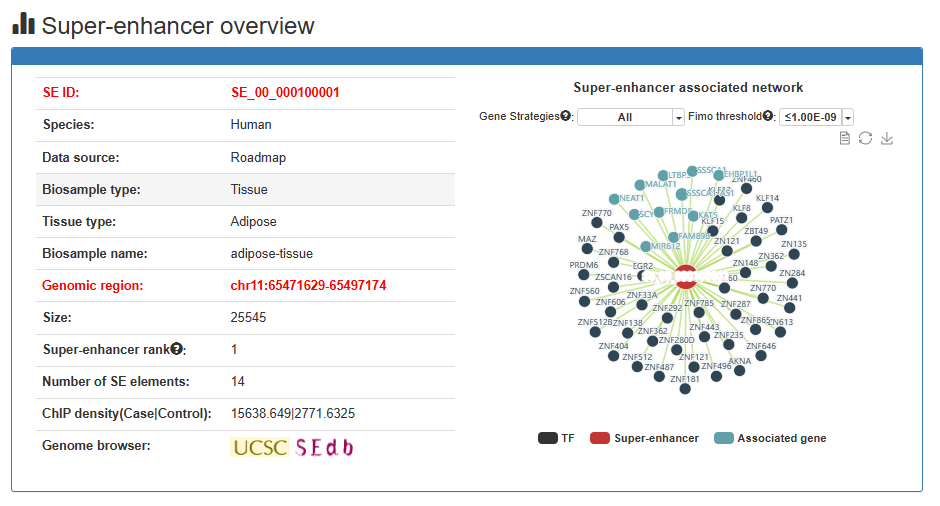
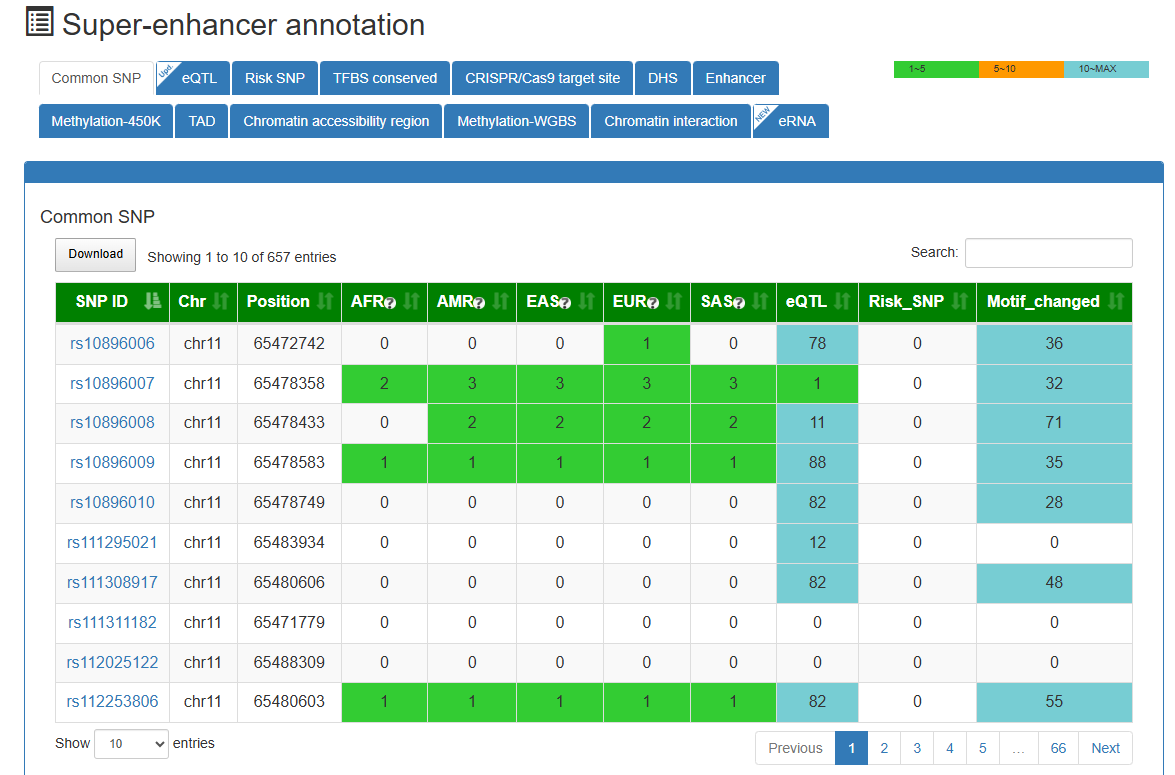
Here, we developed a comprehensive super-enhancer database across multiple species (SEdb 3.0, http://www.licpathway.net/sedb), which aims to provide a large number of available resources on human, mouse, Arabidopsis thaliana and maize super-enhancers. The potential functions of super-enhancers in the regulatory network are also annotated in the database. The current version of SEdb 3.0 has recorded a total of 3,478,186 SEs from 5,387 samples, including 3,389 human samples, 1,962 mouse samples, 21 Arabidopsis thaliana samples and 15 maize samples. Furthermore, SEdb 3.0 also provides detailed genetic and epigenetic annotation information on super-enhancers. The information includes common SNPs, motif changes, expression quantitative trait loci (eQTL), risk SNPs, transcription factor binding sites (TFBSs), CRISPR/Cas9 targets, DNase I hypersensitive sites (DHSs), chromatin accessibility regions, methylation sites, chromatin interaction regions, TADs and eRNAs. For the in-depth analysis of super-enhancers, SEdb 3.0 will help clarify the functions related to super-enhancers and discover potential biological effects.
 The
increase in the dataset size of SEdb 3.0
The
increase in the dataset size of SEdb 3.0
The
increase in the dataset size of SEdb 3.0
 number
of
samples for each tissue type
number
of
samples for each tissue type
number
of
samples for each tissue typeNews and Updates
10/16/2017 Database construction
06/11/2018 The database is online
08/02/2018 Add gene-based and organization-based query capabilities
10/17/2018 SEdb is accepted by Nucleic Acids Research
02/03/2019 SEdb v1.01: Delete a sample (SE_00_002), SEdb now contains 541 samples
03/13/2019 SEdb v1.02: Update the download files to provide super-enhancer associated genes
03/14/2019 SEdb v1.03: Update the page of 'Home' and 'Submit'
05/21/2021 SEdb v1.04: Update the page of 'Data-Browse' and 'Download'
03/18/2022 SEdb v2.00: Add 1198 human sample and 931 mouse sample
06/02/2022 SEdb v2.00: Add Search super-enhancers by TF-based, SE-based TF-Gene analysis and Differential-Overlapping-SE analysis
03/11/2025 SEdb v3.00: Add 1650 human samples, 1031 mouse samples, 21 Arabidopsis thaliana samples and 15 maize samples
05/12/2025 SEdb v3.00: Add SE blast alignment analysis and SE-driven core TF enrichment analysis
Sister Projects
Contact us
Principal Investigator: Chunquan Li, Ph.D.
The First Affiliated Hospital, Hengyang Medical School, University of South China
Email: lcqbio@163.com